Auto Coding tab
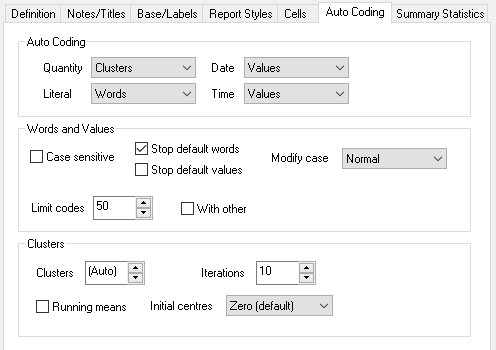
| Area | Description |
| Auto Coding | |
| Quantity | Set to None for no auto coding Set to Clusters to auto categorise the data using a k-means cluster analysis Set to Values to sort the quantity responses into code bands with one code per unique value |
|
Literal |
Set to None for no auto coding Set to Values to create a code for each unique response (so “I like apples” and “I love apples” would have different codes.) Set to Words to create a code for each unique word in a response (so “I like apples” and “I love apples” would have four codes, one each for “I”, “like”, “love” and “apples”) |
|
Date |
Set to None for no auto coding Set to Values to sort date responses into code bands with one code per unique value |
|
Time |
Set to None for no auto coding Set to Values to sort time responses into code bands with one code per unique value |
|
Words and Values |
|
|
Case sensitive |
Create separate codes if responses use different cases. |
|
Stop default words |
Do not code words that are included in the stop list |
|
Stop default values |
Do not code values that are included in the stop list |
|
Modify case |
Change the case of words or phrases to the selected style |
|
Limit codes |
Set the maximum number of codes to be used (maximum number of 2000) |
|
Clusters |
Specify how open-response quantities will be coded into clusters |
|
Clusters |
Set the number of clusters to create |
|
Iterations |
Set how often the algorithm is repeated (higher numbers give greater accuracy but are slower) |
|
Running means |
Check to calculate the cluster centres every time a data case is allocated to a new cluster, rather than waiting until all cases have been evaluated. |
|
Initial Centres |
Specify the starting point of the calculations |
|
|
Set to Zero (default) to start at 0 (in the n-dimensional space). Since the data has been standardised, this should be the centre point of all the variable data |
|
|
Set to First case to use the data in the first respondent case as the starting point |
|
|
Set to Evenly spread to spread the start points evenly across the n-dimensional space |